고정 헤더 영역
상세 컨텐츠
본문
12주차부터 13주차까지는 그간 kaggle을 통해 배운 데이터분석 코드를 활용해 파이썬으로 데이터를 분석하는 프로젝트를 진행했다. 주제는 자유롭게 선택하는 방식이었다. 그래서 팀원과 의논한 후, 풍력발전 데이터와 원자력 발전 데이터를 분석해보기로 했다. 미리 말하자면, 데이터 분석 후에 우리나라 환경에서 풍력발전은 적합하지 않다는 결론에 도달할 수 있었다. 어떤 코드를 사용해서 데이터를 가공하고 그래프를 만들었으며 어떤 데이터를 분석했길래 이런 결론에 도달할 수 있었는지 지금부터 살펴보자.
프로젝트에 사용될 코드들을 본격적으로 작성하기에 앞서 아래의 코드를 실행해준다.
import folium
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rc
import matplotlib.ticker as mticker
from matplotlib.ticker import MultipleLocator
import numpy as nppandas, seaborn, matplotlib.pyplot을 사용해 그래프를 그려줄 것이다. 또한 folium을 사용해 지도를 만들어줄 예정이고 numpy를 사용해 for문을 사용하려고 한다. 위의 코드를 실행했으면 아래로 내려가도록 하자.
아래는 풍력발전소의 발전량을 알아보기 위해 사용한 데이터 프레임의 원본이다(head 함수를 사용해서 앞에서 5개의 데이터만 불러왔다). 이를 불러오는 코드도 아래 첨부했다(파일의 경로는 각자에게 맞도록 수정해서 사용해야함을 잊지말자!).
wind_power_data = pd.read_csv("/Users/username/Desktop/한국전력거래소_시간별 풍력발전량_20211231.csv", encoding = 'cp949')
wind_power_data.head()
이 데이터 프레임을 그대로 사용할 수도 있지만 2019년도의 데이터만을 사용하고 싶기 때문에 아래의 코드를 사용해 데이터를 원하는 형태로 가공해준다.
wind_power_data = pd.read_csv("/Users/username/Desktop/한국전력거래소_시간별 풍력발전량_20211231.csv", encoding = 'cp949')
wpd = wind_power_data[(wind_power_data['거래일자'] > '2018-12-31') & (wind_power_data['거래일자'] < '2020-01-01')]
wpd_graph = wpd.groupby("지역").agg({"발전량(MWh)" : "sum"})
wpd_graph.reset_index().head()간단한 설명을 덧붙이자면 거래일자가 '2019-01-01'인 데이터 부터 '2019-12-31'인 데이터까지 wpd 변수에 입력한다. 그리고 해당 데이터를 'groupby 함수'를 사용해 지역별로 묶어주고 '.agg 함수'를 사용해서 풍력 발전량의 총 합을 나타낸다. 이때 reset_index 함수를 사용해 지역을 하나의 칼럼으로 사용할 수 있게 되돌려 놓는다. 최종적으로, 2019년 한해 동안 각 지역의 총 풍력 발전량을 나타내는 데이터 프레임의 형태로 데이터를 가공해주는 것이다. 그러면 아래 사진과 같은 형태로 나타나게 된다.
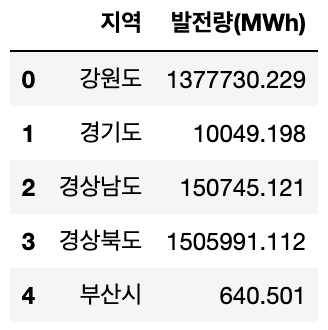
풍력 발전소의 발전량 데이터 가공이 완료되었으니, 이제 원자력 발전소의 발전량 데이터를 가공해보도록 하자. 아래의 데이터가 원자력 발전소 발전량의 원본 데이터이다.
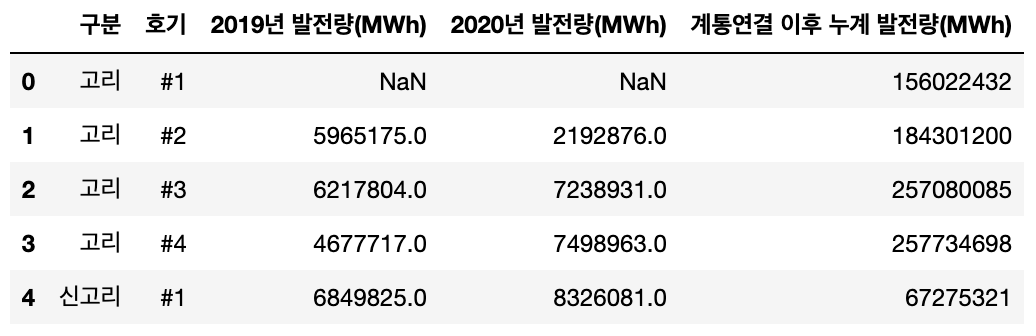
이 데이터 프레임은 2019년도 발전량만을 나타내는 형태로 가공하고 싶었다. 그러나 2020년 발전량 칼럼에서 볼 수 있듯이 2019년 발전량 칼럼에도 곳곳에 NaN(Not a Number) 값이 있었다. 이 NaN 값들은 지금은 폐쇄되어서 발전하지 않는 원자로들에 대한 값이므로 NaN 값은 0으로 처리를 해주고 싶었다. 그래서 fillna(0)을 포함한 아래의 코드를 작성해서 데이터 가공을 진행했다.
Nuclear_power_plant_data = pd.read_csv("/Users/username/Desktop/원자력안전위원회_국내원전 호기별 발전량_20201231.csv", encoding = 'cp949')
Nuclear_power_plant_data["2019년 발전량(MWh)"] = Nuclear_power_plant_data["2019년 발전량(MWh)"].fillna(0)
Nuclear_power_plant_data.loc[:, ['구분','호기', '2019년 발전량(MWh)']].head()결과는 아래 사진과 같다.

이제 앞서 가공한 두 데이터 프레임을 활용해서 그래프를 통한 데이터 분석을 진행해보도록 하자. 먼저, 풍력 발전소의 발전량부터 그래프를 통해 나타내도록하겠다. 그래프를 그려내는 코드는 아래와 같다.
plt.figure(figsize=(8,6))
plt.title('2019년 지역별 풍력발전량(단위: MWh)', fontsize=25,loc='center', pad=20)
sns.barplot(x = '지역', y = '발전량(MWh)', data = wdf_graph.reset_index())
plt.axis([ -0.6, 10.6, 0, 16*100000])
plt.xlabel('지역명', fontsize=20,labelpad=20, loc='center')
plt.ylabel('발전량(MWh)', fontsize=20, labelpad=20, loc='center')
plt.show()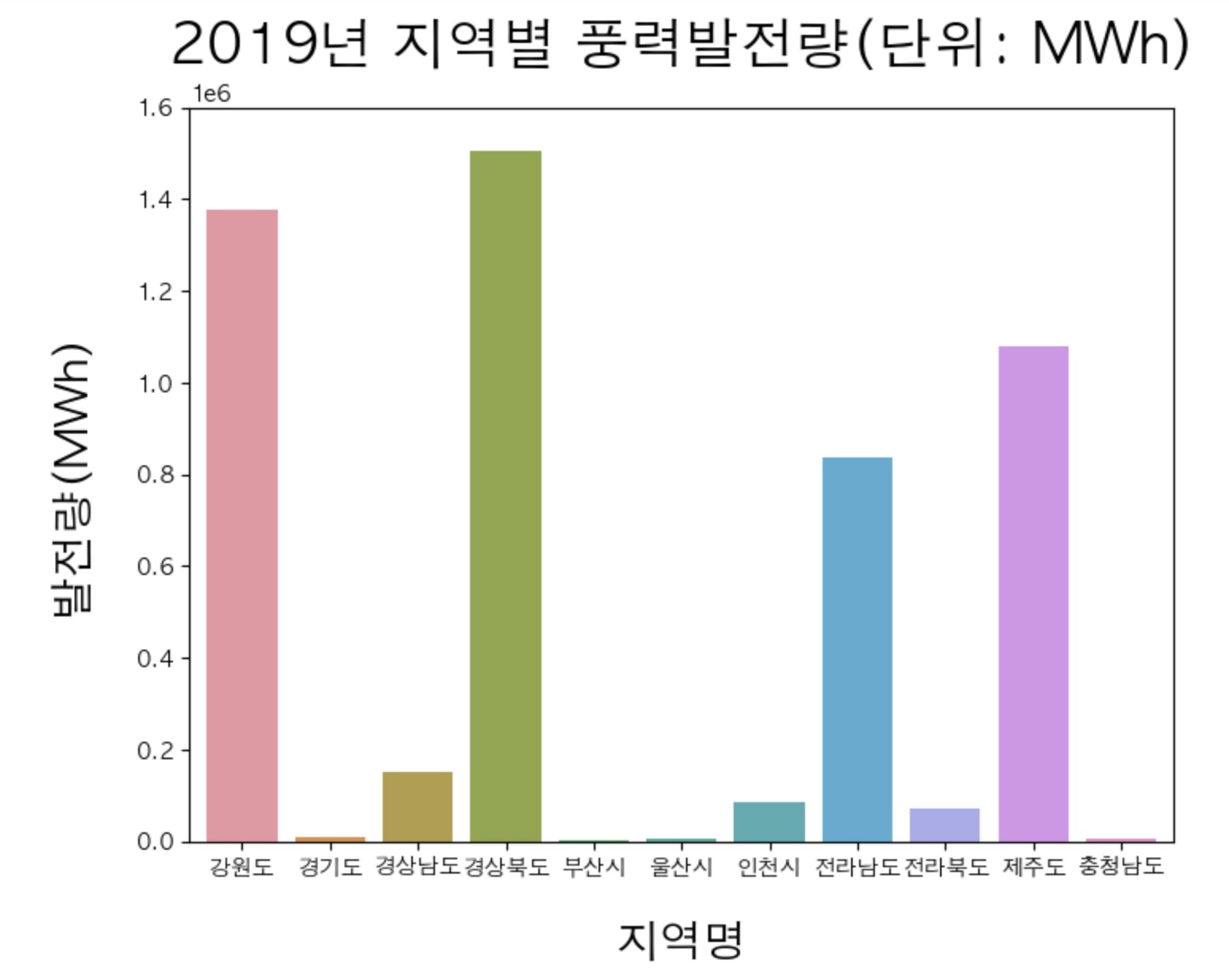
비교 대상이 되어줄 원자력 발전소 발전량 그래프도 코드를 통해 생성해보겠다(글씨체가 깨지는 것을 방지하기 위해 첫줄에 rc함수로 폰트를 처리해줬다).
plt.rc('font', family='AppleGothic')
nppd = Nuclear_power_plant_data.groupby("구분").agg({'2019년 발전량(MWh)' : "sum"})
plt.figure(figsize=(8,6))
plt.title('2019년 원자력 발전소별 발전량(단위: MWh)', fontsize=25,loc='center', pad=20)
sns.barplot( x = '구분', y = '2019년 발전량(MWh)', data = nppd.reset_index())
plt.xlabel('발전소명', fontsize=20,labelpad=20, loc='center')
plt.ylabel('발전량(MWh)', fontsize=20, labelpad=20, loc='center')
plt.show()
자, 이렇게 두개를 놓고 보니 원자력 발전소와 풍력 발전소의 발전량 차이가 그렇게 크게 나지 않는 것 같아 보일 수 있다. 이를 보다 직관적으로 시각화 하기 위해 두 값을 모두 하나의 그래프로 옮겨서 그려보겠다.
plt.plot(nppd.reset_index()['2019년 발전량(MWh)'], 'lightgreen', label = "2019년 원자로별 발전량")
plt.plot(wdf_graph.reset_index()["발전량(MWh)"], 'lightblue',label = "2019년 지역별 풍력 발전량")
plt.legend(loc="best", ncol=1, fontsize=10, frameon=True, shadow=True)
plt.title('2019년도 원자력 발전량과 풍력 발전량 비교 그래프(단위: MWh)', loc='center', pad=10)
plt.axis([-0.5, 11, -0.5*10000000, 4.7*10000000])
plt.ylabel('발전량(MWh)', labelpad=10, loc='center')
plt.xlabel('원자로(고리, 신고리, 신월성, 월성, 한빛, 한울), \n풍력발전(강원도, 경기도, 경상남도, 경상북도, 부산시, \n 울산시, 인천시, 전라남도, 전라북도, 제주도, 충청남도)', labelpad=10, loc='center')
plt.xticks(np.arange(1, 11 ,1))
plt.show()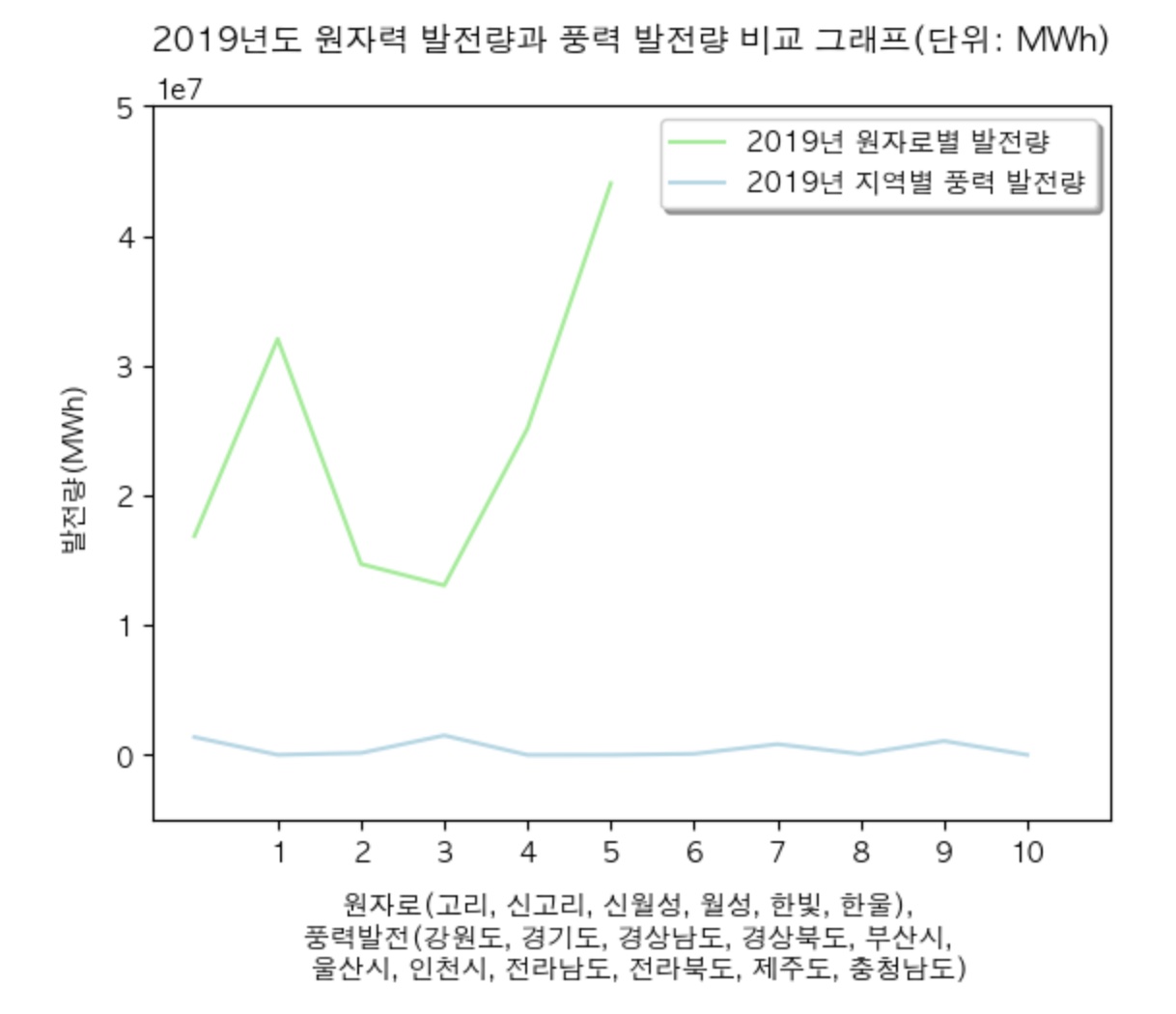
초록색 꺾은 선 그래프가 원자력 발전소의 발전량이고 하늘색 꺾은 선 그래프가 풍력 발전소의 발전량이다. 어떤가? 이제는 보다 직관적으로 얼마나 차이가 나는지 볼 수 있지 않은가? 둘의 비교를 위해 원자력 발전소 그래프의 최하단부 꼭지점의 값과 풍력 발전소 최상단부 꼭지점의 값을 확인해봤다. 각각 13064103, 1505991 로 계산 결과 약 8.7배의 차이가 남을 확인할 수 있었다.
이번에는 지도를 통해서도 둘의 차이점을 알아보도록 하겠다. 먼저, 풍력발전소의 위치 정보 데이터를 가공해준다. 이번에도 선 코드 후 사진으로 첨부하겠다.

wind_loc_data = pd.read_csv("/Users/username/Desktop/한국에너지공단_풍력기 위치정보_20210630.csv", encoding = 'cp949', index_col = 0)
wind_loc_data.loc[:, ['단지명', '분류', '주소', '위도(lat)', '경도(lon)']].head()
원자력 발전소의 위치 정보 데이터 같은 경우에는 따로 찾지 못해서 위키 백과를 참고해 직접 파일을 제작했다. 따라서 따로 불러오는 코드를 보여주진 않겠다. 그럼 바로, 풍력 발전기의 위치 데이터와 원자력 발전소의 위치 데이터를 활용해 지도에 마커로 표시하는 코드와 각각의 지도를 선 코드 후 지도 형식으로 보여주겠다. 풍력 발전기 부터 GoGo!
m = folium.Map(location=[37.547647896577175, 126.94245451708481], zoom_start=6, width = 500, height = 500)
folium.TileLayer("Stamen Terrain").add_to(m)
folium.LayerControl().add_to(m)
lat = wind_loc_data['위도(lat)']
lon = wind_loc_data['경도(lon)']
for i,j in zip(lat, lon):
folium.Marker([i,j], popup="Wind Power", tooltip="풍력발전기", icon = folium.Icon(color = 'blue', icon = 'fa-solid fa-fan', prefix = 'fa-solid')).add_to(m)
m변수 m에 Stamen Terrain 형식의 지도를 담아줄 예정이라 folium을 사용해 코드를 작성했다. 그리고 데이터의 위도와 경도를 각각 lat, lon 변수에 저장한다. 끝으로 for 문을 활용해 lat, lon 을 위도, 경도로 하는 마커를 전부 변수 m에 추가한 뒤 m을 출력하면 아래 사진과 같은 지도를 얻을 수 있다.
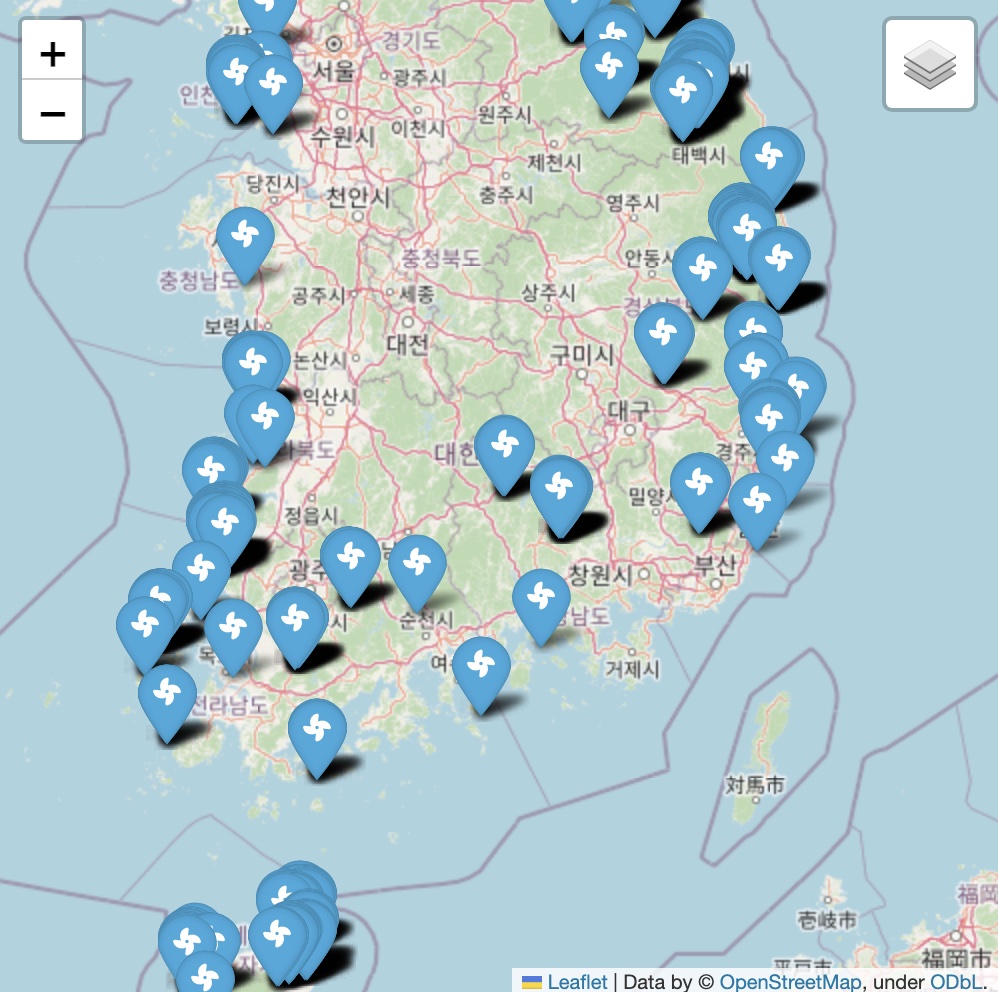
같은 방식으로 원자력 발전소의 지도를 생성해준다.
m2 = folium.Map(location=[37.547647896577175, 126.94245451708481], zoom_start=6, width = 500, height = 500)
folium.TileLayer("Stamen Terrain").add_to(m2)
folium.LayerControl().add_to(m2)
lat = Nuclear_power_plant_loc['위도(lat)']
lon = Nuclear_power_plant_loc['경도(lon)']
for i,j in zip(lat, lon):
folium.Marker([i,j], popup="Nuclear Power Plant", tooltip="원자력발전소", icon = folium.Icon(color = 'green', icon = 'fa-solid fa-circle-radiation', prefix = 'fa-solid')).add_to(m2)
m2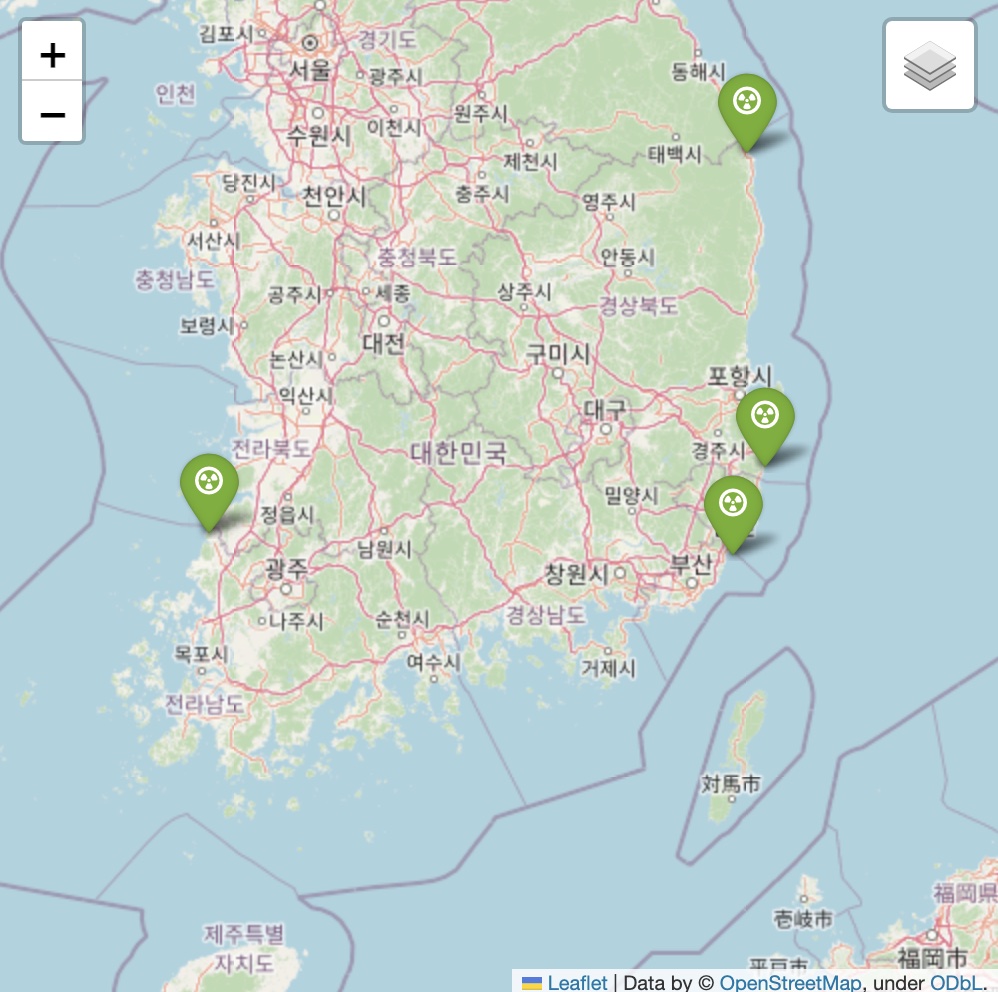
약간 의아해하실 분들이 계실 수도 있겠다. 분명 앞서 원자력 발전소는 총 6개였는데 지도에 마커는 4개 밖에 없으니 말이다. 이건 사실 위키 백과를 참고하다가 발생한 일이다. 원자력 발전소의 위경도 데이터를 만들던 중 신월성 발전소와 신고리 발전소는 각각 기존의 월성, 고리 발전소 인근 지역에 건설되었다는 것을 알게되었다. 따라서 굳이 추가적으로 표현할 필요가 없다고 판단했고 그래서 지금과 같은 지도를 얻게 되었다. 혹여나 의아해하실 분들을 위해 설명드렸다.
이제 다시 본론으로 돌아와서 두 지도를 비교, 분석해보자. 원자력 발전소의 경우에는 바다와 인접한 전국 4개 지역에만 건설되어있으며 경관을 해치지도 않고 자연 환경의 파괴가 적다. 반면에 풍력 발전기의 경우 전국각지의 산과 바다에 설치되어있으며 이로 인해 자연 경관 훼손은 기본이고 환경도 많이 파괴된다. 그럼에도 효율 역시 원자력 발전소에 한참 미치지 못함을 알 수 있다.
그렇다면, 대체 왜? 풍력 발전기가 전국 각지에 저렇게도 많이 설치되어 있음에도 발전량이 원자력 발전소에 비해 미미할까? 이를 알아보기 위해 기상청의 전국 풍속 데이터를 가져와봤다. 아래는 전국 풍속 데이터의 원본이다.

위 데이터에서 최대 풍속과 평균 풍속 칼럼만 가져와서 전국의 최대, 평균 풍속 그래프를 만들어봤다.
plt.figure(figsize=(55,12))
plt.title('전국 풍력 발전소의 연간 최대 풍속, 평균 풍속', fontsize=55,loc='center', pad=30)
plt.rcParams['font.family'] = 'AppleGothic'
sns.lineplot(wind_d_data['최대 풍속(m/s)'], label="각 지역의 최대 풍속(m/s)")
sns.lineplot(wind_d_data['평균 풍속(m/s)'], label="각 지역의 평균 풍속(m/s)")
plt.legend(loc="best", ncol=1, fontsize=50, frameon=True, shadow=True)
plt.axis([-1, 96, 0, 11])
plt.xlabel('지역명', fontsize=50,labelpad=20, loc='center')
plt.ylabel('풍속(m/s)', fontsize=50, labelpad=20, loc='center')
plt.yticks([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], fontsize = 40)
plt.hlines(6, 0, 95, color='green', linestyle='solid', linewidth=3)
plt.hlines(4, 0, 95, color='red', linestyle='solid', linewidth=3)
plt.savefig('전국 풍력 발전소 연간 최대,평균 풍속 그래프', dpi =100, facecolor='#eeeeee',
bbox_inches='tight', pad_inches=0.3)
plt.show()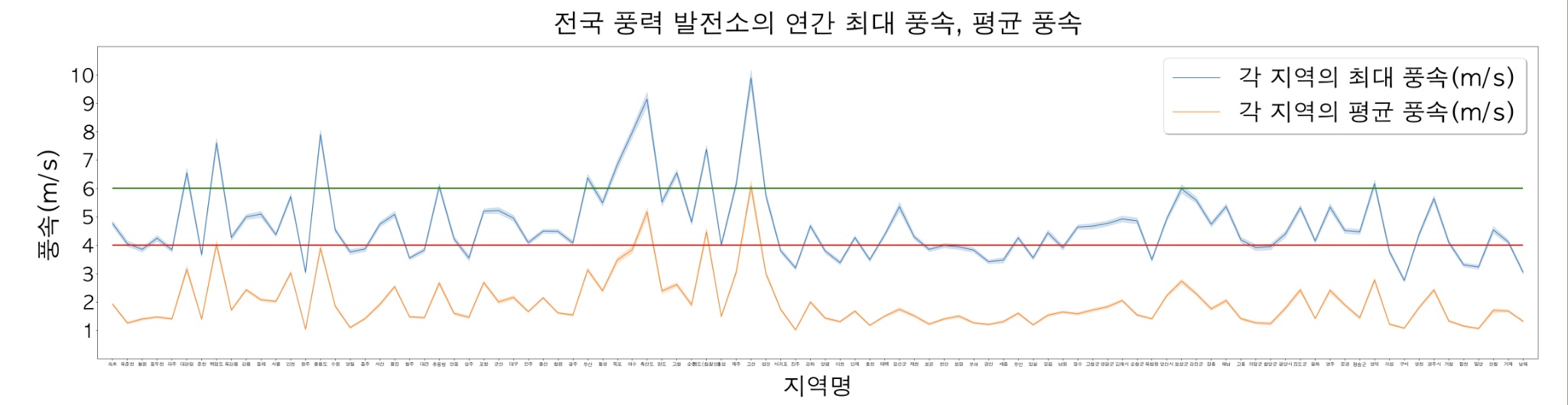
여기서 hlines 함수를 사용해서 4m/s와 6m/s에 각각 선을 그어줬다. 이 선의 의미를 이해하기 위해선 배경지식이 필요한데 이 부분은 아래 기사를 통해서 참고할 수 있었다. 당신의 생각보다는 간단하지 않은 풍력발전(저자: 이진오)
당신의 생각보다는 간단하지 않은 풍력발전 - 시사IN
풍력발전기는 ‘외모’ 때문에 손해를 본다. 보기 좋고 듬직한 것도 한두 개 서 있을 때 얘기다. 여러 개가 떼 지어 있는 모습을 보면 생각이 바뀐다. 바람이 잘 부는 곳에 설치한다고 산등성이
www.sisain.co.kr
핵심 내용을 요약하면 풍력 발전이 가동하기 위해서는 4m/s의 풍속이 필요하고 풍력 발전을 통해 실질적인 이득일 보기 위해서는 6m/s의 풍속이 필요하다는 것이다. 그러나 위의 그래프를 보면 평균적으로 6m/s의 바람이 부는 곳은 전국에 1곳뿐이고 4m/s의 바람이 부는 곳도 많지 않음을 알 수 있다. 즉, 우리나라의 자연환경에서는 풍력발전을 하기에 충분한 바람이 불지 않고 따라서, 현재 단계의 풍력 발전은 우리나라에 맞지 않음을 알 수 있다는 것이 나의 결론이었다.
이번 프로젝트가 개인적으로는 진행하면서 가장 재밌었다. 학부 시절 다뤄봤던 내용을 데이터 분석 프로젝트를 통해 더 자세하게 분석할 수 있어서 좋았다. 그리고 프로젝트를 진행하면서 점점 더 프로그래밍이 일상에 얼마나 녹아있는 지를 알게 된 것 같다. 예전에는 순수하게 User로서 프로그램을 봐 왔다면 이제는 해당 프로그램의 개발자의 노고를 약간은 느낄 수 있는 단계에 온 것 같다. 어느 덧 약 3개월 가량 열심히 프로그래밍을 배워온 보람이 있는 느낌적인 느낌? 그럼 오늘 포스팅은 여기에서 마무리 하도록 하겠다. 모두들 안녕히.
'[포스코x코딩온] 스마트 팩토리 SW 개발자 과정 회고록' 카테고리의 다른 글
| [포스코x코딩온] 스마트 팩토리 SW 개발자 과정 14 주차 프로젝트 회고 | 취업 준비(영상 피드백, 회사 탐색) (0) | 2023.06.30 |
|---|---|
| [포스코x코딩온] 스마트 팩토리 SW 개발자 과정 14 주차 프로젝트 회고 | 취업 준비(1분 자기소개서 작성팁, 면접시 참고사항) (0) | 2023.06.29 |
| [포스코x코딩온] 스마트 팩토리 SW 개발자 과정 12 주차 회고 | 데이터 분석(with kaggle) (0) | 2023.06.09 |
| [포스코x코딩온] 스마트 팩토리 SW 개발자 과정 11 주차 회고 | 파이썬 반복문 (0) | 2023.06.04 |
| [포스코x코딩온] 스마트 팩토리 SW 개발자 과정 10 주차 회고 | 신호등 PLC 프로젝트 (0) | 2023.05.25 |




